
この程OpenAI社がPrismという科学論文支援システムを開発した。しかしながら政治・経済の記事を書いていると懸念もあると感じる。
つまり要諦を間違えると、生産性を高めようとしたAI作業が返って泥沼化する可能性がある。つまり元のデータやコンセプトがしっかりしていないと、生成過程で様々な問題が生じる。これを後工程で修正することはできないのだ。

ニュースをまとめているとChatGPTやGeminiがもたらす情報は非常に有効だと感じる。そして政治ブログを書いている程度ではAI経由の情報が混じってもあまり問題にならない。そもそもオリジナリティよりも「まとめ」のほうが重要視されるからである。
しかし懸念もある。記事を書いた後でプロモーションのためにGeminiに要約をさせていて発見したことがある。
記事が不完全だと間を埋めるハルシネーションが起きる。また、Geminiはいつもトランプ大統領を次期大統領だと誤認する。オリジナル学習データがアップデートされておらず、ユーザーの指摘で改めて記事を更新する仕組みになっているのである。このため一度要約させてて情報をアップデートしたり、オリジナル原稿を書き直す(AIが類推によるハルシネーションを起こすということはユーザーも誤認する可能性がある)必要があると発見した。
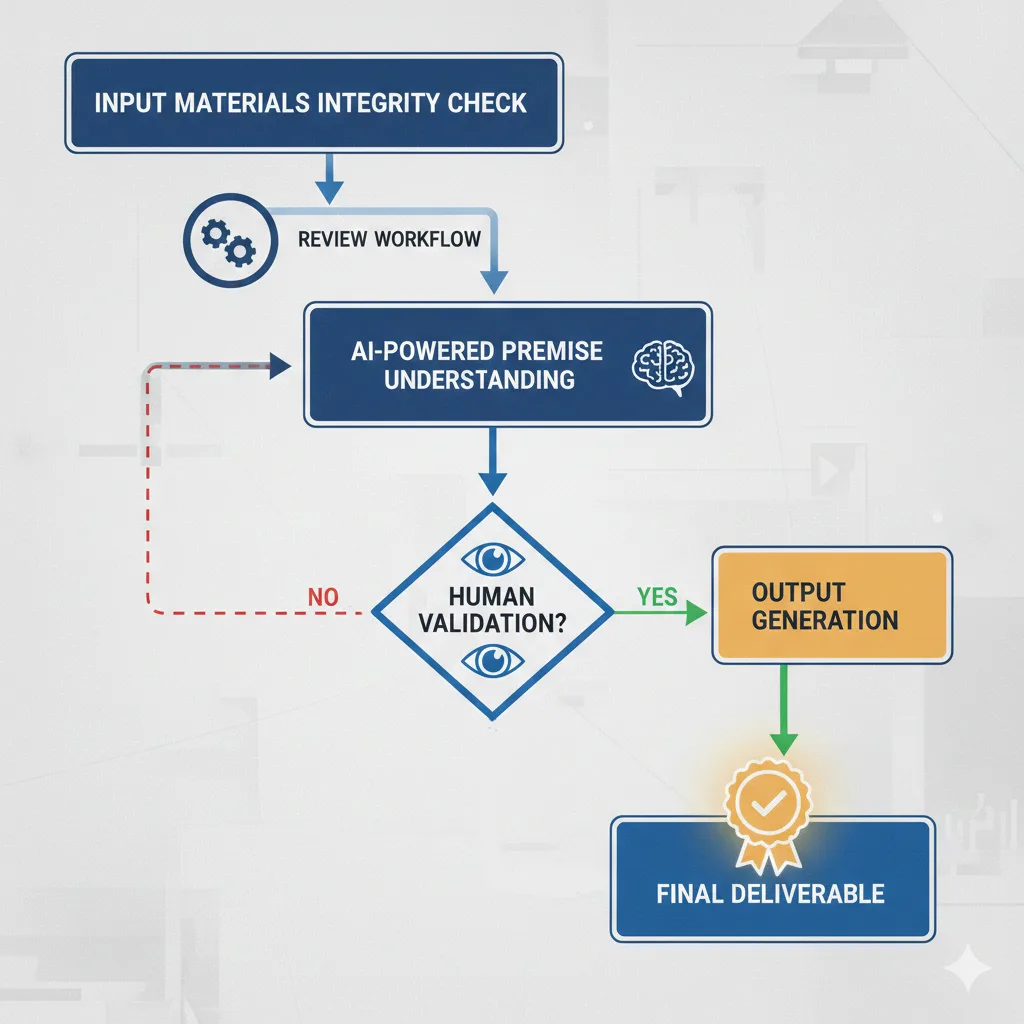
簡単な文章要約でもこの体たらくなのだから論文の出力を制御するのはかなり大変だろうなあと感じたのだ。誤解を恐れずに言えば「この程度の間違いはいいや」位の気持ちがないとAI生成は(少なくとも今は)使えない。

おそらくOpenAI社はこうした問題を把握しているはずだが、1%の間違いを冒してでも技術進歩を優先し、問題が出てきたら後で修正する道を選んだのだろう。
OpenAI社はすでに論文の純粋さを保持するために出典管理、引用明示、生成過程のトレーサビリティ確保といった技術的・運用的対策を講じており
- 出典強制・引用前提設計(最重要)
- 生成ログ・トレーサビリティの保持
- 「著者ではなく支援ツール」とする明確な位置づけ
- 推論と事実の分離(Speculation Guard)
- データ汚染(Data Contamination)対策
論文の純粋さを保持するために、出典強制、生成過程の可視化、著者責任の人間帰属、推論と事実の分離、学習データ汚染防止といった多層的な対策を講じている。
同時に、生成モデルが本質的に不完全であり、誤りや推論補完(ハルシネーション)を完全に排除できないことも理解した上でシステム設計を行っている
- ハルシネーションは「バグ」ではなく「構造的必然」
- 「常に最新で正しいAI」は存在しないという前提
- ユーザーも誤認する、という前提に立っている
つまり、OpenAI社もシステムの不完全さについても理解しており、ハルシネーションや知識の陳腐化、ユーザー側の誤認といったリスクを前提とした上で、運用と検証によって補正されることを想定した設計を採用していると言えるのだ。
Googleも同じように思考過程を公開することで人間がプロセスを後日検証できるような仕組みを準備している。
今回のシステムは科学技術論文を対象にしているが、AIの限界を理解することは政治ブログからビジネス文書の作成まで、あらゆる文書作成に共通して有効である。

最近「多くのビジネス文書をAIでがっちゃこ=統合してペライチ=A4一枚の資料にしましょう」というCMを見かけた。しかしこれは、そもそもそれらの資料が同一の前提やソースを共有し、論理的に矛盾していないことを暗黙の前提としている。
仮に資料の前提に矛盾があれば、AIはそれを解消しようとして整合性の高い説明を生成するが、その結果として事実とは異なる「滑りの良い説明」が生まれる可能性がある。
最終成果物を人間が確認するという前提は、AI技術が発展しても、少なくとも当面は不可欠な要件であり続けるだろう。
コメントを残す